TopK 系统设计
文章目录
TopK问题
TopK问题是常见的排行榜问题,比如youtube浏览量最多的前50个视频,twitter点赞最多的post等等..
在数据规模比较小的时候可以考虑使用最大堆实现,如果需要近实时计算,或者亿级数据规模下就会有性能瓶颈了.
基于Count-Min Sketch的方案
Count-Min Sketch是一种概率数据结构,用于高效地估计数据流中元素的频率。

Count-Min Sketch的计算流程如下:
- 初始化:首先,创建一个二维数组(也称为哈希表或者Sketch),并初始化所有元素为0。这个二维数组有d行,w列,其中d是哈希函数的数量,w是哈希表的大小。
- 更新:当一个新的元素x到来时,对每一个哈希函数h_i (i从1到d),计算哈希值h_i(x),并将对应的哈希表位置的计数器加1。
- 查询:当需要查询一个元素x的频率时,对每一个哈希函数h_i (i从1到d),计算哈希值h_i(x),并取所有对应的哈希表位置的计数器的最小值作为频率的估计。
以下是使用Go语言实现Count-Min Sketch的基本计算流程的代码:
|
|
count-min sketch只是是一种概率数据结构,用于高效地估计数据流中元素的频率。然而,它本身并不能直接找到前K个频率最高的元素。为了找到前K个频率最高的元素,我们需要结合使用其他数据结构,例如优先队列(Priority Queue)。
以下是一个基本的步骤:
- 首先,我们使用Count-Min Sketch来处理数据流,为每个元素计算其频率的估计值。
- 然后,我们使用一个大小为K的优先队列来跟踪频率最高的K个元素。优先队列中的元素按照其频率的估计值排序,频率最低的元素位于队列的顶部。
- 当我们遇到一个新的元素时,我们首先使用Count-Min Sketch来计算其频率的估计值。然后,我们将这个元素和优先队列顶部的元素进行比较。如果新元素的频率更高,我们就将队列顶部的元素移除,并将新元素添加到队列中。
- 最后,优先队列中的K个元素就是频率最高的K个元素。
这种方法的优点是,它可以在处理大规模数据流的情况下,以较小的内存和计算开销找到频率最高的K个元素。然而,由于Count-Min Sketch是一种概率数据结构,所以这种方法可能会有一定的误差。
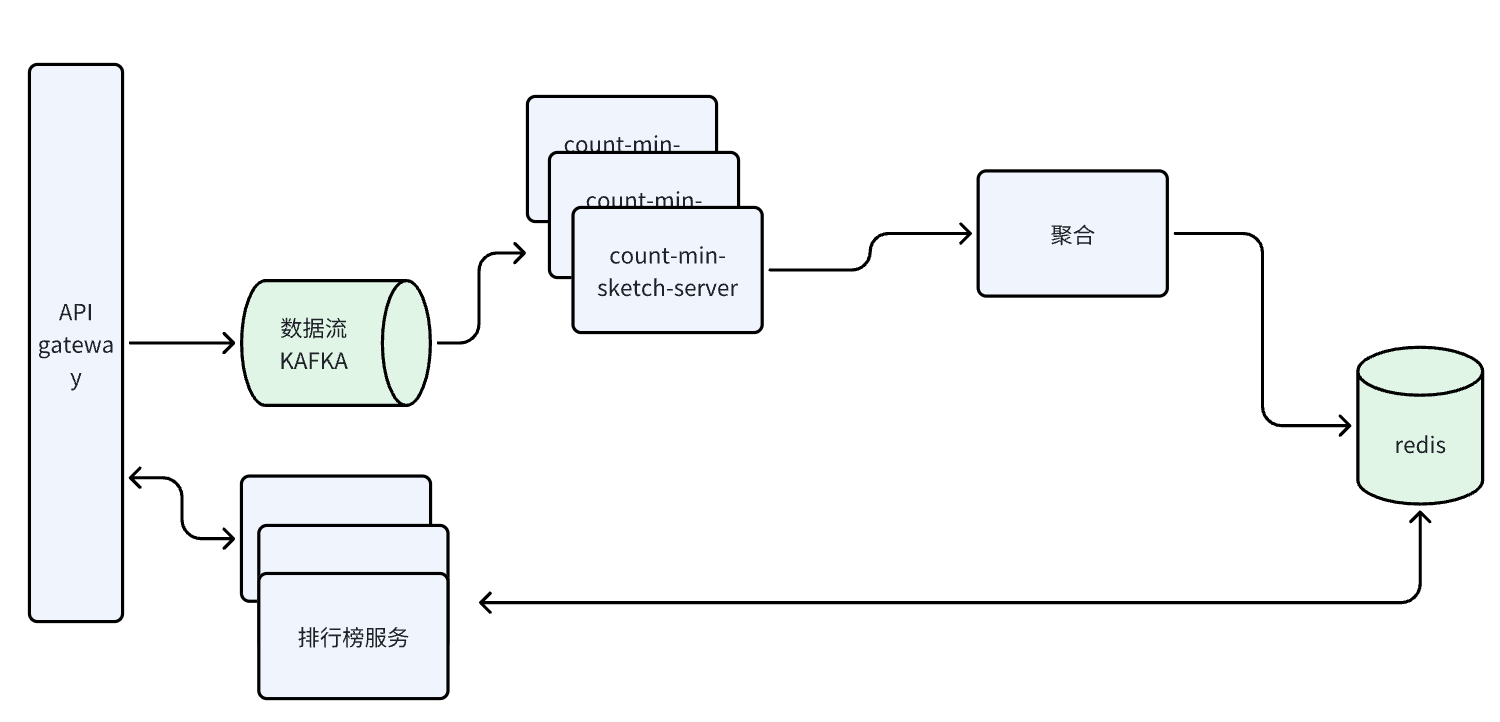
最终方案
在分布式系统中使用Count-Min Sketch,各节点每1分钟生成一个Count-Min Sketch,并有一个聚合服务每一分钟就聚合一次所有结点上的最小堆数据,生成每分钟的topK,:
- 数据分布:你可以选择将数据流分布到各个节点。这可以通过哈希函数实现,例如,你可以使用数据元素的哈希值对节点数量取模,来决定将数据元素发送到哪个节点。
- 在每个节点上使用Count-Min Sketch:每个节点接收到数据元素后,使用Count-Min Sketch来计算元素的频率。每个节点都会维护一个自己的Count-Min Sketch数据结构。
- 结果合并:当需要获取全局的频率估计时,你需要合并各个节点的Count-Min Sketch。由于Count-Min Sketch的结构是一个二维表格,你可以通过将同一位置的计数器相加,来合并各个节点的Count-Min Sketch。
参考
文章作者 bobo
上次更新 2024-01-04